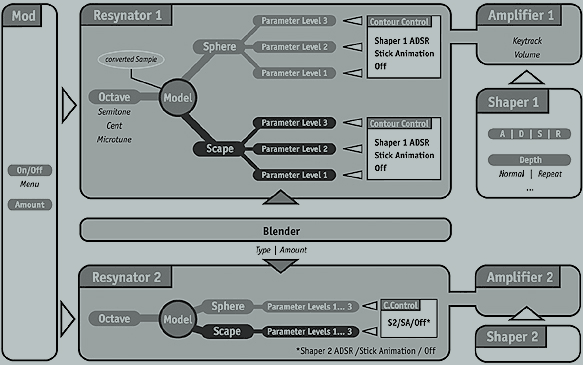
 The <Neuron> audio synthesis engine uses what is called a „Multi Component Particle Transform Synthesis“, a form of synthesis which could be best described as „adaptive Resynthesis”. To reproduce sounds electronically with this synthesis it is necessary to first analyze the audio signal and convert it in a form usable by the Neuron Audio System. In the case of the <Neuron> synthesizer, this is done in a separate cross-platform application called the „Model Maker”. With this software application, sampled sounds are converted into a synthesis model the <Neuron> can utilize to resynthesize sounds.
The <Neuron> audio synthesis engine uses what is called a „Multi Component Particle Transform Synthesis“, a form of synthesis which could be best described as „adaptive Resynthesis”. To reproduce sounds electronically with this synthesis it is necessary to first analyze the audio signal and convert it in a form usable by the Neuron Audio System. In the case of the <Neuron> synthesizer, this is done in a separate cross-platform application called the „Model Maker”. With this software application, sampled sounds are converted into a synthesis model the <Neuron> can utilize to resynthesize sounds.
Resynthesis – Historical Background
The concept of „Resynthesis” was introduced in the 1980s to describe a form of sound synthesis that builds an arbitrary sound from a sum of sine tones of different frequencies and amplitudes. Several hundred sine tones were mixed at appropriate frequencies and amplitudes to recreate the spectrum of an analyzed sound. This was a very clever concept: sine tones are simple trigonometric building blocks that are relatively easy to generate using analogue and digital oscillators and they perfectly represent the notion of „frequency”, since any such tone has one single, constant frequency.
 |
The Hartmann <Neuron> Synthesizer introduced in 2003 is still one of the most unusual synthesizers today. It has been awarded several prestiguous prices for innovation and outstanding design. Developed by leading industry designer Axel Hartmann using sound synthesis technology from our company this synthesizer is a much sought after piece of equipment, even years after the Hartmann company has gone out of business in 2005 over a dispute with their worldwide distributor. |
This concept, on the other hand had to struggle with severe disadvantages. Aside from being almost unusable in practice (no human being can operate a synthesizer that requires controlling several hundred of sine tones at a time) it had inherent technical problems: sine tones are periodic (after a certain amount of time, they repeat their shape) and have no localization in time (they do not have a beginning and an end). Therefore, they are perfectly suited to synthesizing periodic signals that have a constant frequency, but it is difficult to resynthesize signals that have a short duration and are impulsive in nature. In most sounds and music, both types of signals can occur, either sequentially or in combination. This is the reason why most resynthesized signals sound diffuse and reverberant, they suffer from an effect called „phasiness”.
One step further
However, there are other forms of resynthesis that do not rely on sine tones as basic building blocks. A popular example would be the Wavelet Transform, which does not use sine tones as „basis”, but rather more complex animals called „Wavelets”.
 In practice, there is an almost infinite amount of different bases that allow building complex sounds by adding, translating, scaling and convolving them. Each of these bases has its own unique properties, along with its own unique advantages and disadvantages.
In practice, there is an almost infinite amount of different bases that allow building complex sounds by adding, translating, scaling and convolving them. Each of these bases has its own unique properties, along with its own unique advantages and disadvantages.
You may have encountered the popular picture that shows how one could construct a sawtooth wave by adding different sinewaves. In this process, one resynthesizes a complex sawtooth wave by adding sinewaves of different frequency and amplitude. The sawtooth wave is build from a sine basis.
Of course, you could also do the reverse. Based on adding a bunch of sawtooth waves of different amplitudes and frequencies, you could resynthesize a simple sine wave.
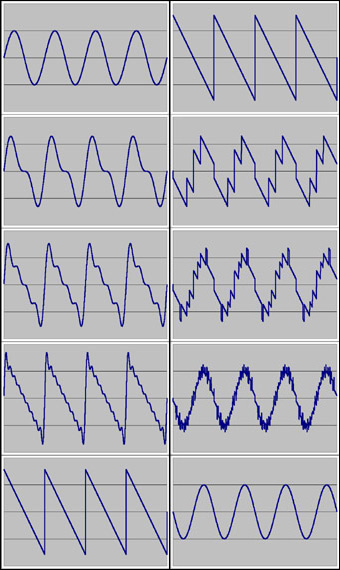 Illustration: Sinewaves can be used to build a more complex waveform like a sawtooth wave, but sawtooth waveforms can in turn be used to resynthesize a simple sinewave. From top to bottom, more waves are used at each stage. The left sequence builds a sawtooth wave from sine waves, the right sequence builds a sine wave from sawtooth waves. Click image to enlarge.
Illustration: Sinewaves can be used to build a more complex waveform like a sawtooth wave, but sawtooth waveforms can in turn be used to resynthesize a simple sinewave. From top to bottom, more waves are used at each stage. The left sequence builds a sawtooth wave from sine waves, the right sequence builds a sine wave from sawtooth waves. Click image to enlarge.
If we adapt the basis used for resynthesis to the sound that is to be resynthesized and its inherent sonic qualities we get a very efficient representation of that sound which is also custom tailored to its sonic qualities.
Custom tailored
The Neuron Audio System uses a type of resynthesis where the synthesis itself is adapted to the sound. The basis function(s) used to resynthesize this sound are determined by evaluating its underlying model. It is this concept that allows not only a faithful reproduction but also a vast variety of modifications of the basic instrument.
To synthesize the sound, the underlying model of the sound generator has to be estimated from and adapted to the sonic qualities of the original sampled sound. The Neuron System analyzes both the type of vibrating medium as well as the resonant corpus used to shape the sound. This process is computationally very demanding, which is why it is done at the analysis stage. A pattern recognition process based on Artificial Neural Networks is used to create a model from the sound. If the sound cannot be uniquely represented by a single model (which may be the case for drum loops and complete musical pieces) it is constructed from a time variable morph between different models representing the sound at that instant.
After the pattern recognition stage, the basic model is subsequently refined and its parameters are adjusted in a way to reproduce the original sound as accurately as possible. The accuracy is determined by the „Complexity parameter” inside the ModelMaker application. Complex models are built from a set of simpler models, up to the limit set by the complexity constraint. Basic properties such as the size of the resonant body, material and esasticity (determined and accessed through the so-called Parameter set) can be influenced and combined from other models during the resynthesis.
 Mainz, Germany, December 8th, 2011 — Software developer Tom Zicarelli has released an open source iOS audio processing graph demonstration called “audioGraph”. According to the author the work is in part based on the DSP Dimension pitch shifting tutorial.
Mainz, Germany, December 8th, 2011 — Software developer Tom Zicarelli has released an open source iOS audio processing graph demonstration called “audioGraph”. According to the author the work is in part based on the DSP Dimension pitch shifting tutorial. Stephan M. Bernsee talks about developing the Prosoniq morph plug in
Stephan M. Bernsee talks about developing the Prosoniq morph plug in
 © 2026 Zynaptiq GmbH, All Rights Reserved. Use or reproduction of materials from this site prohibited unless explicitly granted in writing.
© 2026 Zynaptiq GmbH, All Rights Reserved. Use or reproduction of materials from this site prohibited unless explicitly granted in writing.